
genular ⓑ
Unifying genes and cells with biological knowledge for deep insights
This is a demo database interface. Results are limited to a small (100) subset of data. For full access, please use the API or download the data dumps.
What's this all about?
Genular is a database that integrates single-cell RNA sequencing data with genomic and proteomic information, encompassing over 125 million unique cells from diverse tissues and conditions. It aims to uncover how genes function within specific cell types across immunity, development, and disease. A unique feature is the Cell Significance Index (CSI) which highlights genes exhibiting truly distinctive behavior within a single integrated platform.
- Cross linking data and discovery: Every gene entry integrates gene expressions, protein data, interaction networks, and disease associations all in one searchable interface.
- Cell significance index (CSI): CSI metric pinpoints which genes stand out in any given cell type helping to quickly spot critical regulators of immune states, tissue differentiation and pathological processes.
- Pathways and networks: Go beyond raw expression: explore the functional networks and pathways your genes are part of, and discover how they shape complex traits like macrophage reprogramming or T cell memory.
- Advanced filtering: Zoom in on specific conditions like T cells under viral infection to isolate the genes that matter most, and see how they connect to broader regulatory systems.
Genular podcast: genes, cells, and discoveries [deep dive]
Genes
58M
Proteins
9.4M
Unique Cells
125M
In Silico Hypothesis Testing
Go beyond search with Virtual Cell Designer to test ideas before you hit the lab.
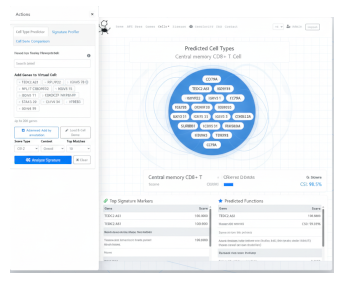
Cell Type Predictor
Input a list of genes and instantly discover the closest matching real world cell type. Go from a gene signature to a cell identity in seconds.
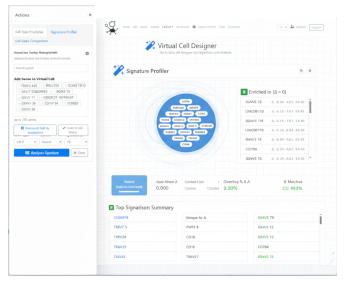
Signature Profiler
Directly compare two gene signatures such as healthy vs. diseased to pinpoint unique markers and shared pathways for target discovery.

Cell State Comparison
Analyze how a cells signature changes between different biological contexts (e.g., resting vs. activated) to uncover drivers of cell state transitions.
Explore Our Richly Annotated Data
Dive deep into comprehensive pages for every gene and cell in our database.

The Gene Centric View
Every gene has a story. Our gene pages provide a 360-degree view, integrating expression data across all cell types with functional annotations, protein information, and pathways. Use our powerful CSI scores to see where a gene is most significantly active and explore AI generated summaries and testable hypotheses.
Explore Gene CD8A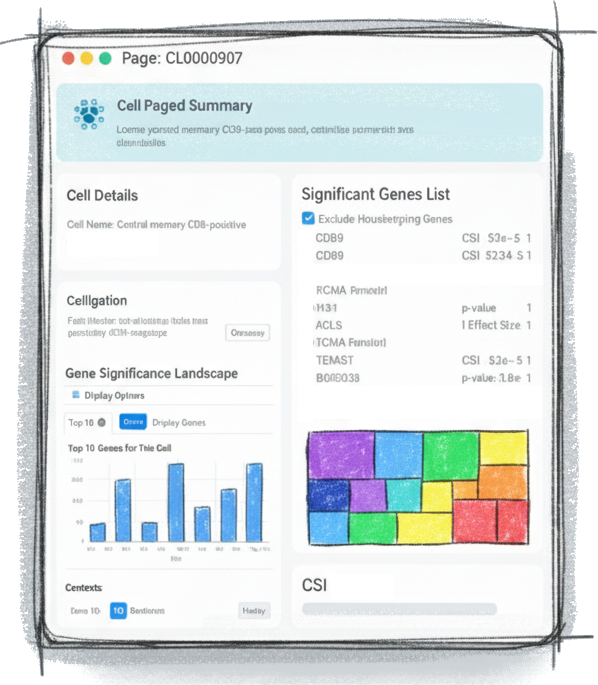
The Cell Centric View
What makes a cell unique? Our cell pages reveal the ranked list of genes that most specifically define a cells identity in any biological context. Filter by CSI, rCSI, or PRS to discover the top genetic markers, investigate housekeeping genes, and understand the molecular signature that drives cellular function.
Explore a T Cell